In itemis, apart from core model driven software development, we also work on certain research projects. In this project, I was involved in a proof of concept for autonomous vehicles. An edge device like Jetson Nano could serve as a CPU in an autonomous vehicle.
The goal of the work is to make a deep neural network capable to recognise traffic lights on a Jetson Nano. In layman terms, Object detection is the key behind detecting different objects in a particular scene or an image in a video. The neural network is created for the purpose by training a neural network or retraining an existing neural network. The process of retraining the network is called Transfer Learning. Transfer Learning is the process of training an existing neural network for custom needs.
Components involved
- NVIDIA Jetson Nano - NVIDIA Jetson Nano is an edge device with 128 cores GPU capable mainly designed to do some deep learning inference on the edge.
- Powerful GPU based environment for training the neural network - In the project, we used PC equipped with NVIDIA RTX 3080 graphic card.

Research
In this section, I elaborate the research required to arrive at the workflow.
- For a professional with very little machine learning and deep learning knowledge, Custom Vision served as a good start point. We used the built-in tool Custom Vision to tag objects in the images. Then, Custom Vision performs transfer learning, using the general neural network YOLOv2. The result of the training is a neural network model of type YOLOv2 in ONNX format. Nvidia Jetson Nano has the capability to convert an ONNX model using TensorRT. When the model is transferred to Jetson Nano device and run, some of the nodes of the model were not compatible and the inference failed. But this part of the work gave me a good overview on how a computer vision problem must be approached. With this knowledge, I proceeded to look for alternatives.
- When exploring further, I found a way to tag images extracted from CARLA simulator using VOTT. For the work, we only tag them with 3 labels, i.e. Stop (red light), Go (green light) and Warn (yellow light). The created dataset will assign such tag to each image. The tagged images can then be extracted as Pascal VOC dataset. Now that I have the images and their tags, I’ll just need to look for how to use them to train a network.
- For the training process, I used a Jupyter notebook on a GPU environment. There are different ways of making the model run on Jetson Nano.
Workflow
Now let’s go through the resulting workflow in more detail. That’s how the data are flowing now:
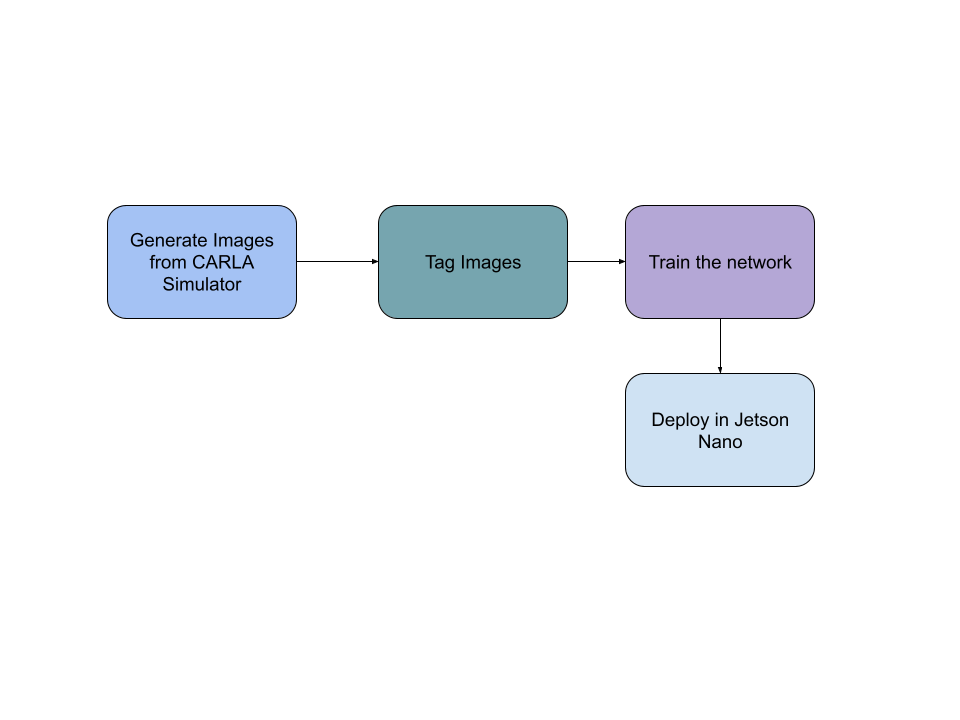
Scenario Simulation
First of all, the data required for the training can be gathered from open source datasets like DriveU traffic lights dataset, but for various reasons we didn’t want to go for that. We’d rather generate our own images with CARLA simulator and tag them by hand. Following is an image from our CARLA simulation scenario:

Image Tagging and Dataset Generation
Based on the images, we tagged known objects. The tagging is done by surrounding the objects and marking the names. This could be done by several tools. In the work we used VoTT. The following steps are a simple description of tagging and naming. For detailed explanation of VoTT usage, please refer the official website.
Step 1: Tagging using VoTT
In this screenshot, I’m placing a rectangle to mark that traffic light in the back in VoTT.
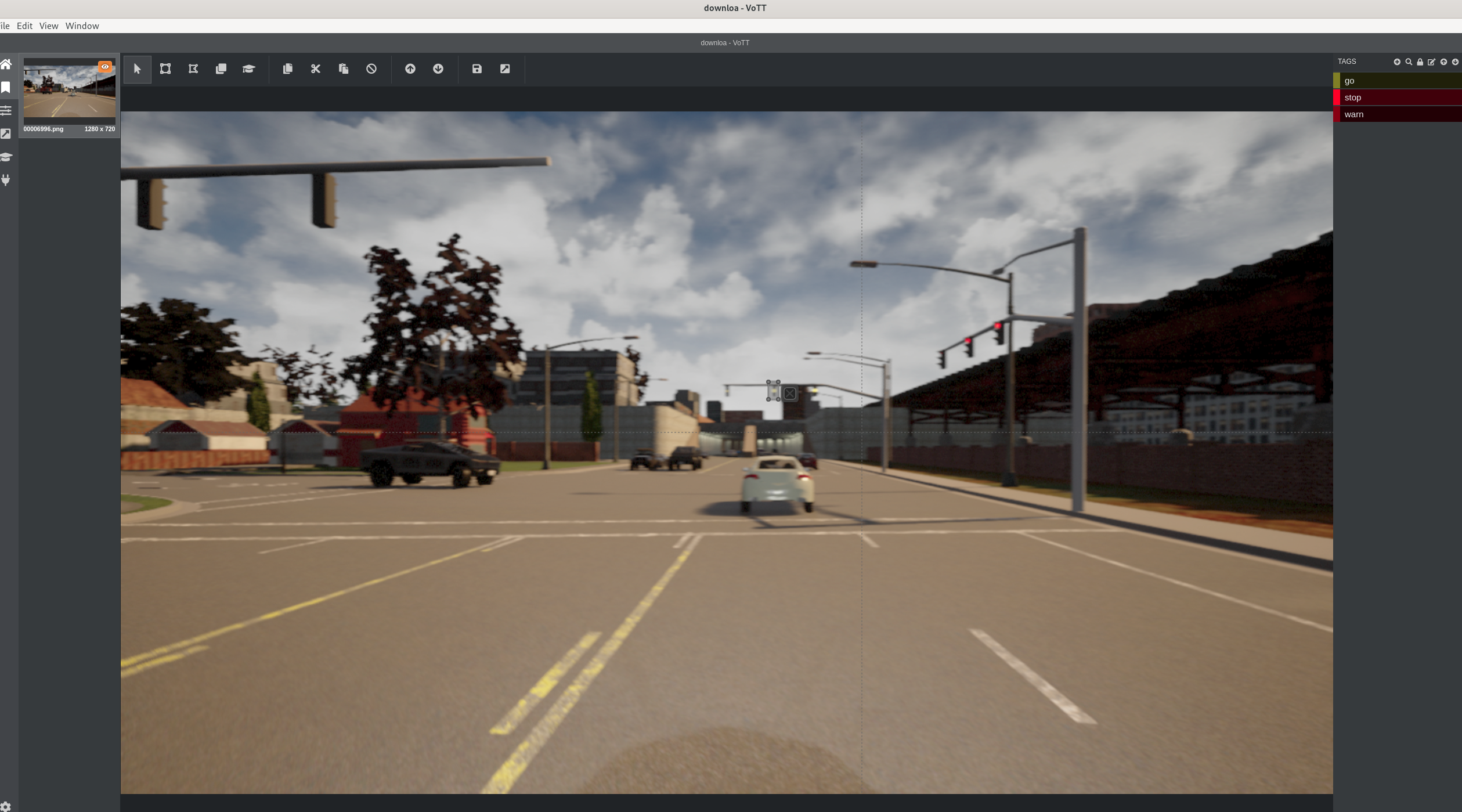
Step 2: Naming the tagged object
Here, I labelled the rectangle as Warning.

Training
We ran the transfer learning with Microsoft Azure’s Custom Vision. It already has the capability to allow the users to tag images and then perform transfer learning on a You only look once (YOLO) neural network, but we didn’t use it. Instead, we used our dataset from the CARLA Simulator and VOTT as the source for transfer learning. Peculiarly, the neural network that will be used is decided in the process. Neural networks designed for object detection are evaluated by FPS (Frames Per Second). According to that, neural networks that base on Single Shot Detector (SSD) performed better than the YOLO network. In this work, we used Google COLAB to train the neural network. The framework used to train the neural network is Google’s Tensorflow.
Deployment
Neural networks are composed of different layers and nodes. Unless it is a CPU based environment, the environment on which a neural network is deployed must be compatible with all the components of that network. For example, some GPU based low level devices don’t support particular operations. Thus, we needed to convert our deep learning neural network model to a model that is supported by the platform we use for object detection. Again, there are several ways of doing this. For example, the training of a neural network could end up in a model in ONNX format. As per the official documentation, ONNX is a generic format to represent deep learning models. We deployed our ONNX model onto the Jetson Nano using ONNXRuntime. ONNXRuntime has to be built specifically for the platform where it is supposed to run the ONNX models on. A second way of deploying the neural network model is to convert the model to tensorRT, which is a native format of the Jetson platform. We went for the third way, which is a mix of tensorflow and tensorRT. In this method, the nodes of the neural network that could be converted to native tensorRT form are converted and other nodes are made to be available in tensorflow form.
Summary
The setup helps to deploy a neural network model into Jetson Nano. When a video is given as input, number of frames that were processed on an average per second was 9. We later improved the value by constructing a neural network from scratch. This setup is part of the Robocar developed at itemis. Following is an image from the output obtained for object detection when passing a CARLA scenario as video input.
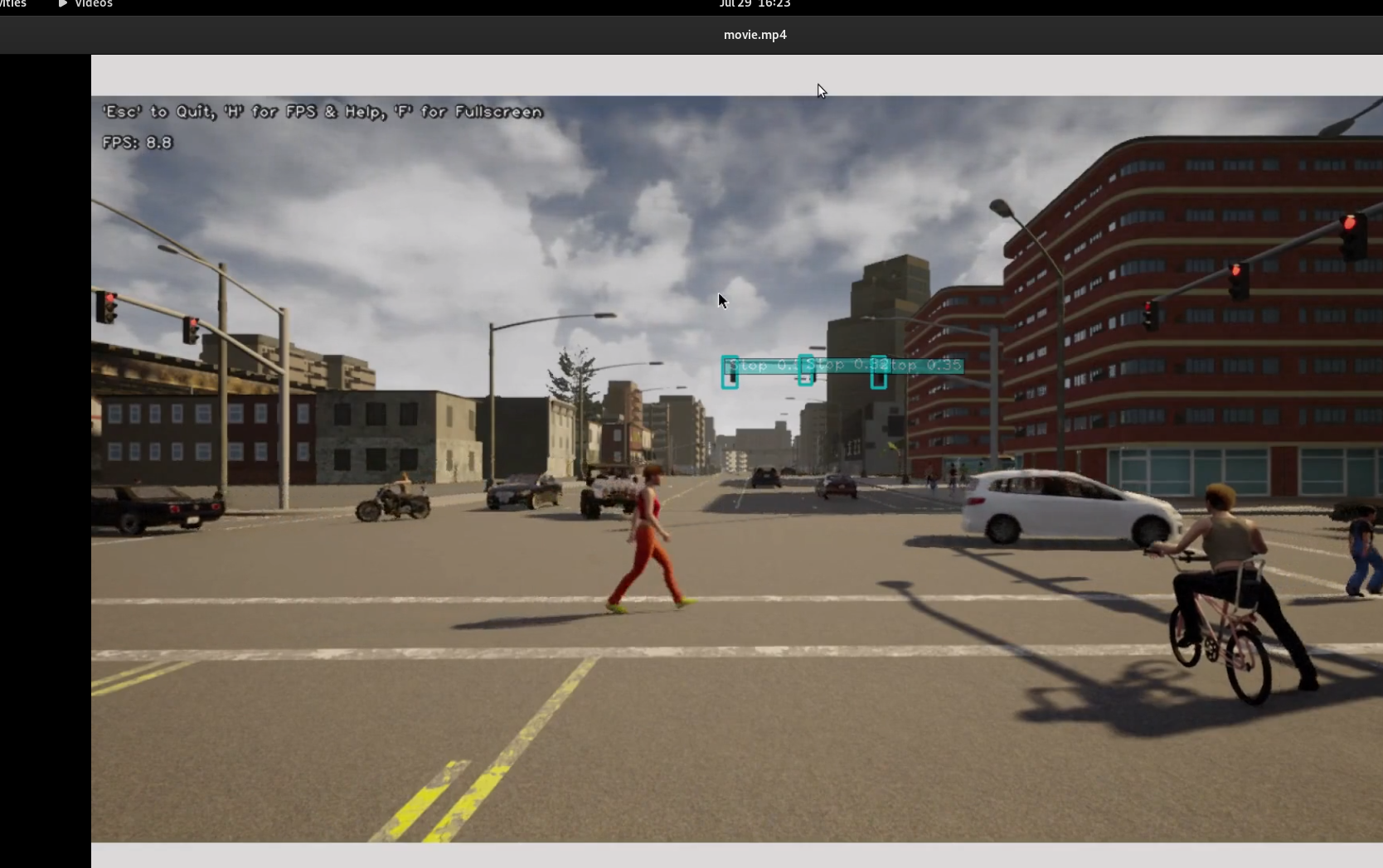
This is how we approached the traffic detection problem in a research project. If such a workflow comes into picture in a business setting, I would bring Model Driven Software Development (MDSD) tooling into the game. It could really help us out in bringing these levels of abstraction together, like generalizing the handling of datasets, creation of neural networks and performing the transfer learning using existing neural networks. Having the network created from a model-driven toolchain would also ease deploying it into high end and low level devices like advanced ECUs in modern vehicles.