Microsoft Word Copy link to clipboard
Data access Copy link to clipboard
The ANALYZE adapter for Microsoft Word provides access to the contents of Word documents as traceable artifacts.
Configuration Copy link to clipboard
Open the ANALYZE configuration with the ANALYZE configuration editor, and add a new data access as described in section "Data accesses". Select Microsoft Word as data access type.
Within the configuration panel, you may specify file patterns consisting of Eclipse projects, folders or file name patterns describing Word files relevant for ANALYZE. Supported Word formats are DOC, DOCX, and DOCM.
Supported keywords:
- resource – A pattern for a project, folder or file in the workspace.
- undefined attribute value – Specifies the value to be returned when an attribute can’t be resolved. This value will be returned if the cell does not exist when trying to retrieve the value from a cell in a Word table (either because the requested cell index is out of bounds or because the table does not contain the requested cell header). Possible values are strings, in which case the returned value will always be the same, or the default keyword.
- default – For undefined attribute value, using the default value will return a String indicating the position that couldn’t be found (either by index, or by column/row header). For example, „<Not a cell: {-4; RowHeader}>”. This is especially useful to detect errors in the configuration or in a Word document
The configuration may contain several resource definitions.
Example:
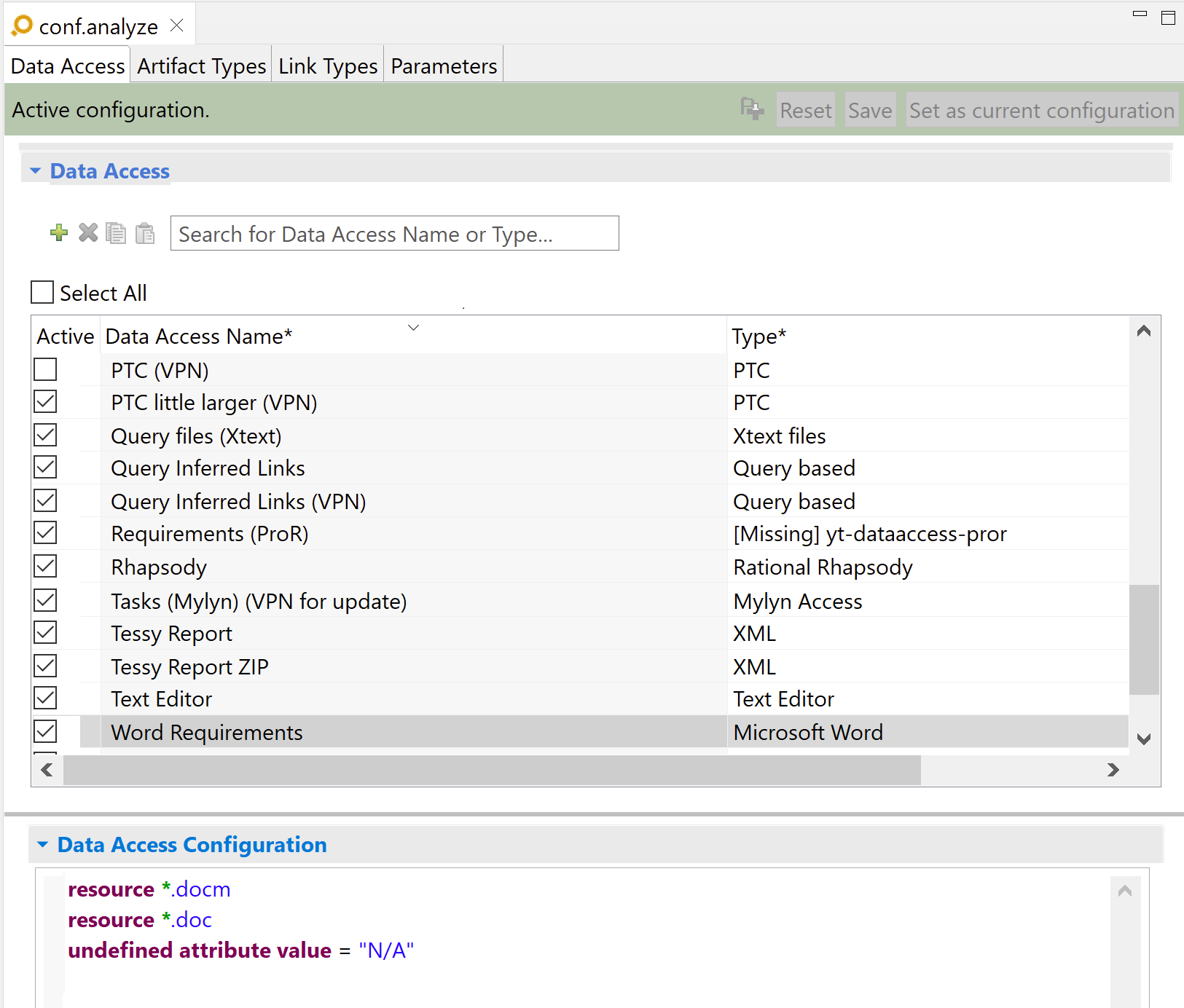
resource *.docm
resource *.doc
undefined attribute value "N/A"
This configuration will match all Word documents in formats DOC or DOCM. If the artifact type configuration matches elements in a Word table and some attributes reference cells that can’t be found, these attributes will receive the „N/A” value.
Artifact type Copy link to clipboard
The Word adapter recognizes three different kinds of artifacts: Bookmarks, regular expression matches, and headings. It supports DOC, DOCM, and DOCX file formats. It can extract information for the mapped attributes from the general structure (headings, paragraphs, tables), and include or exclude artifacts based on their style information (bold/italic/underline/strikethrough).
For example, it is possible to retrieve all bookmarked elements, excluding the ones with the „strikethrough” style.
When the Word change tracking mode is enabled, all modifications will be considered as „Accepted” by ANALYZE. This means that elements marked for deletion (but still visible in the document due to change tracking) will be ignored, whereas added elements will be included. This is useful to avoid duplicate matches, when a paragraph has been modified in change tracking mode, and both the old version and new version are still present in the document.
Configuration Copy link to clipboard
Open the ANALYZE configuration with the ANALYZE configuration editor, and add a new artifact type as described in section "Artifact types". Select your previously-configured Microsoft Word data access in the Data access drop-down list.
Supported options:
- locate bookmark where subset – Specifies bookmark recognition(s). This can be used to filter valid bookmarks by defining a regular expression on the full label format (see detailed explanation below).
- locate text where pattern matches – Searches in the entire document for text matching the specified regular expression. An artifact will be created for each text sequence matching this expression
- locate heading where pattern matches – Searches in the document headings for text matching the specified regular expression. An artifact will be created for each text sequence matching this expression
- where style is (not) – For bookmarks, text or headings, specify additional filter(s) based on font style. Supported font styles are bold, italic, underline and strikethrough. You may specify several style filters. A style is considered to be applied if at least one character has the specified style. Conversely, a style is considered to not be applied if no character has the specified style
- name – Specifies the name for the recognized artifacts. See the list of possible values below
- map – Starts an attribute mapping group
Possible values for name and attribute mappings:
- Generally valid:
name and
map are string concatenations. Possible parts in this concatenations are:
- String literal : a (static) string
- hasStyle(style): evaluates the font style of the matched element and returns true if it has the specified style, false otherwise. Supported font styles are bold, italic, underline and strikethrough. Example: hasStyle(bold).
- For artifacts found in tables:
-
valueOf {x;y} – If the artifact (text or bookmark) is found in a table cell, attributes can be mapped to values in nearby cells. Here
x and
y are integer coordinate values representing a relative cell position, with
x being the column offset and
y being the row offset. The coordinates
0;0denote the current cell. Example:-
{+1;0}indicates the cell that is at one column to the right from the matched artifact’s cell. -
{-1;-3}indicates the cell one column to the left and three rows above the matched artifact’s cell.
-
- column with header – In valueOf {x;y}, x can be replaced by column with header "headerName". In this case, the label of the cells in the first row (top-most) will be used to find the column.
- row with header – In valueOf {x;y}, y can be replaced by row with header "headerName". In this case, the label of the cells in the first column (left-most) will be used to find the row.
-
valueOf {x;y} – If the artifact (text or bookmark) is found in a table cell, attributes can be mapped to values in nearby cells. Here
x and
y are integer coordinate values representing a relative cell position, with
x being the column offset and
y being the row offset. The coordinates
- For
map only:
- Document.property(title) and Document.property(creator): Accesses the Word document’s standard properties title and creator. – Please note: These are Microsoft Word’s metadata, not the metadata of the Word file, i.e., they have to be maintained inside the Word document.
- Document.userProperty(„property_name”): Accesses the Word document’s custom property of the same name.
Use bookmarks as artifacts Copy link to clipboard
The „locate bookmark” matcher can be used to create an artifact for each Word bookmark matching the specified subset (defined as a regular expression)
Minimal configuration:
locate bookmark where subset ".*" {
}
This configuration will create an artifact for each bookmark, with a default name (conforming to the full label format below) and no attributes
This matcher accepts one parameter, in the form of a regular expression, which will be evaluated against the full label of the bookmark. In the minimal example above, the regular expression „.*” matches all available bookmarks (including hidden bookmarks, such as table of contents references)
Full label format for bookmarks Copy link to clipboard
When using the „locate bookmark” matcher, the bookmarks are specified by a string consisting of three sections which are separated by three hash signs:
bookmark_id ### bookmark_content ### (optional_bookmark_desc | …)
The „subset” defines a regular expression, which will be evaluated against this full label: an artifact will be created for each bookmark matching the specified expression. See Bookmark examples below for more details
Please note: The optional_bookmark_desc is deprecated, but still maintained for backward compatibility. It won’t be discussed here.
Additional supported values for bookmarks Copy link to clipboard
When using a ‚locate bookmark’ matcher, you can refer to groups defined in the regular expression, using „$n”, where n is the n-th group (e.g., „$1” is the first group, as defined in the bookmark regular expression)
For example:
locate bookmark where subset "(.*)" {
name "$1"
}
In this example, the parentheses in the regular expression define a group. Then, the value „$1” is a reference to the text matched by the first group (which is also the only group, in this small example)
Bookmark example Copy link to clipboard
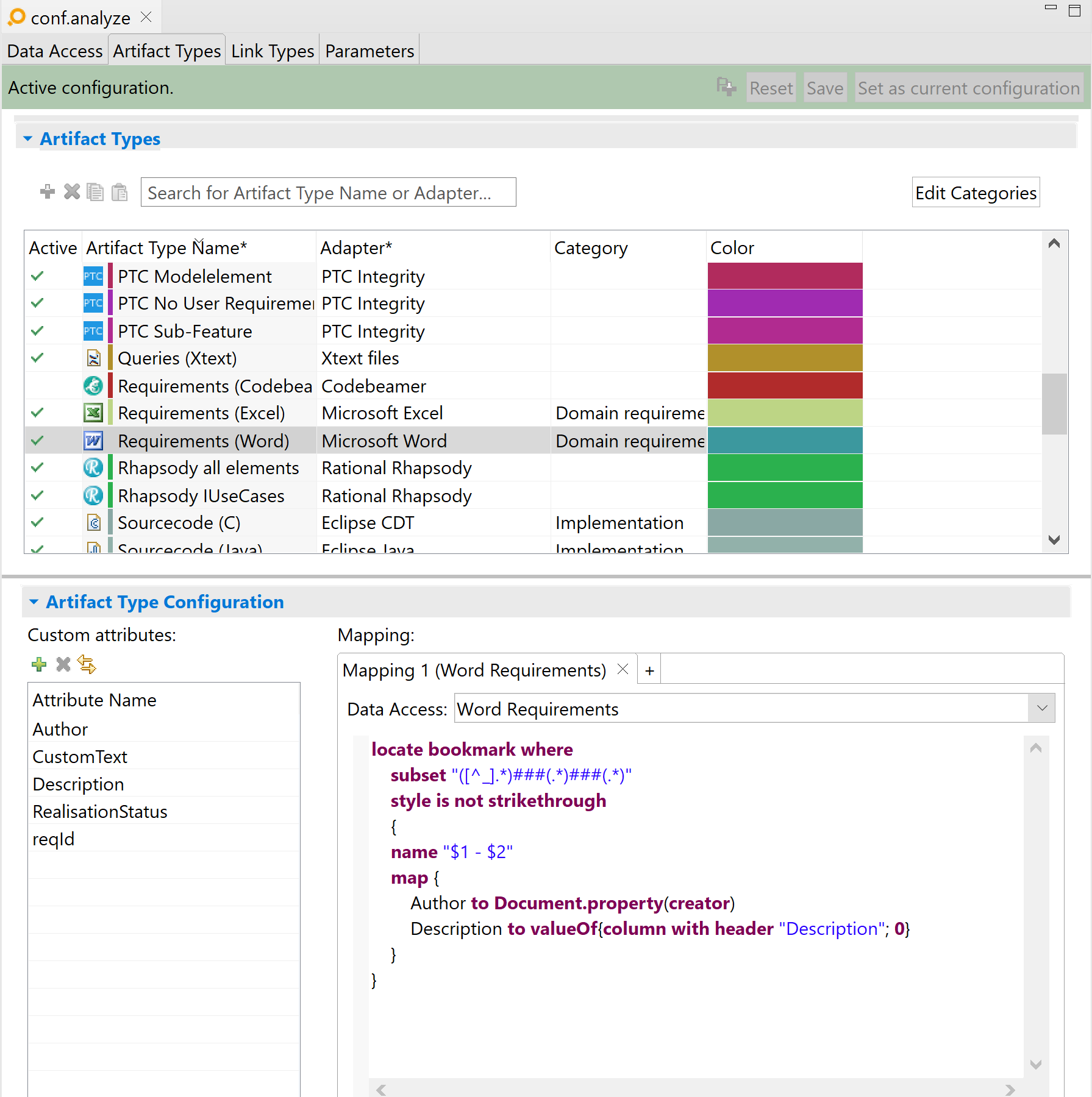
locate bookmark where
subset "([^_].*)###(.*)###(.*)"
style is not strikethrough
{
name "$1 - $2"
map {
Author to Document.property(creator)
Description to valueOf{column with header "Description"; 0}
}
}
- In the above example, bookmarks will be located in all documents specified by the Word Requirements data access.
- The subset is a regular expression indicating that all bookmarks should be selected, except the ones prefixed with an underscore „_”. Microsoft Word uses an underscore prefix to identify „hidden bookmarks”, which means that this expression will only match visible bookmarks:
-
([^_].*): Defines a group (identified by the parentheses). The group will match any sequence of characters which does not start with an underscore -
###: The first „full label format” separator. The text before this separator represents the bookmark ID, whereas the text after this separator represents the bookmarked text -
(.*): Defines a second group, matching any sequence of characters -
###: The second (and last) „full label format” separator. The text before this separator represents the bookmarked text -
(.*): Defines a third group, matching any sequence of characters
-
- The
$1 and
$2 expressions in the identifier refer to groups of the
subset, hence ANALYZE will show matched bookmarks as concatenation of
bookmark_id + " - " + bookmark_content. - The option style is not strikethrough will skip all bookmarks with at least one strikethrough character in the bookmarked text.
- If the bookmarked text is located in a table cell, the description will be retrieved from a cell on the same row, namely the cell in the column named „Description”. The name of a column is the text of the first cell (top-most) in this column. If this column can’t be found, the value specified in the Word Requirements data access will be used instead.
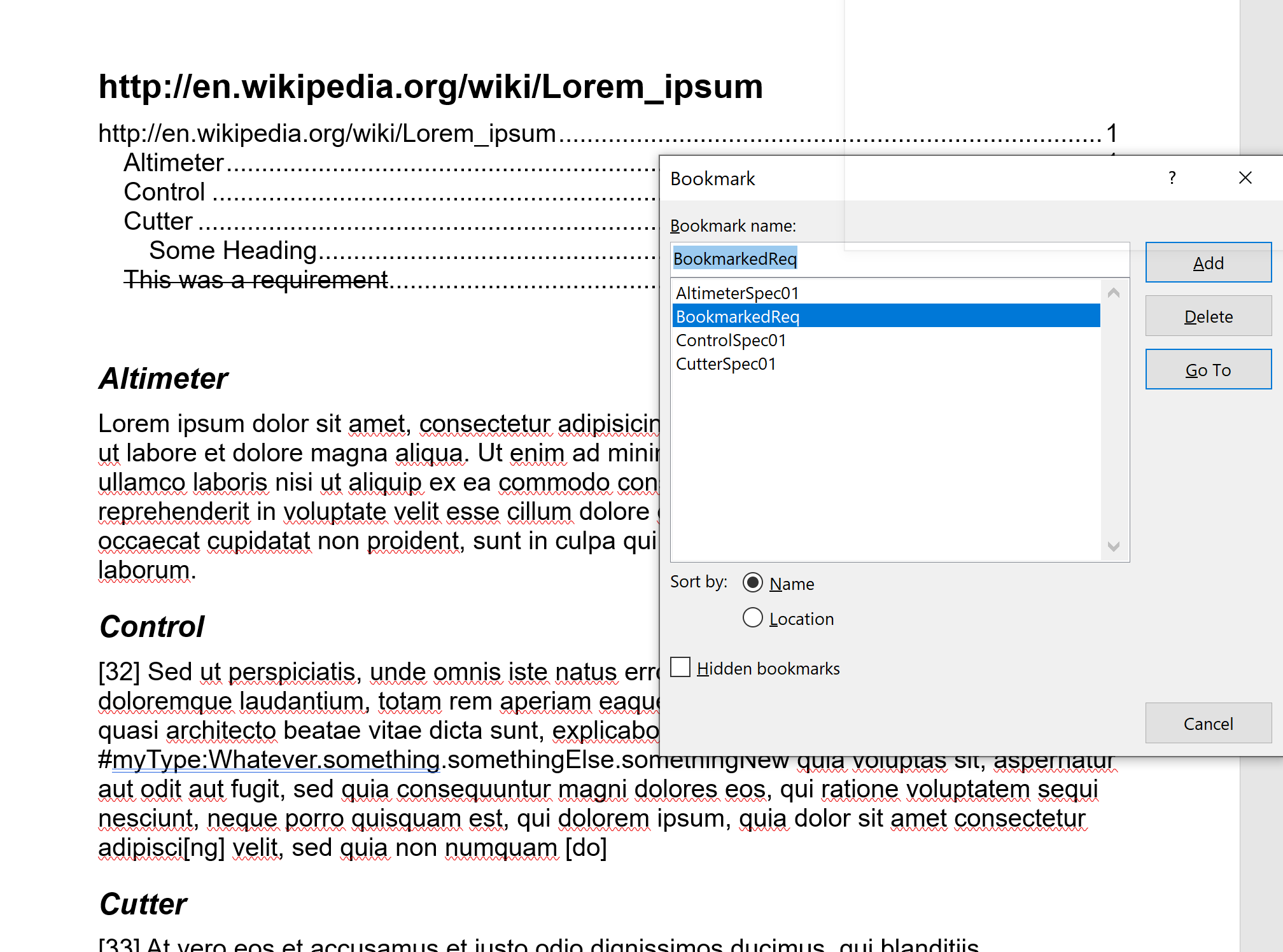
Here is a sample Word document using bookmarks:
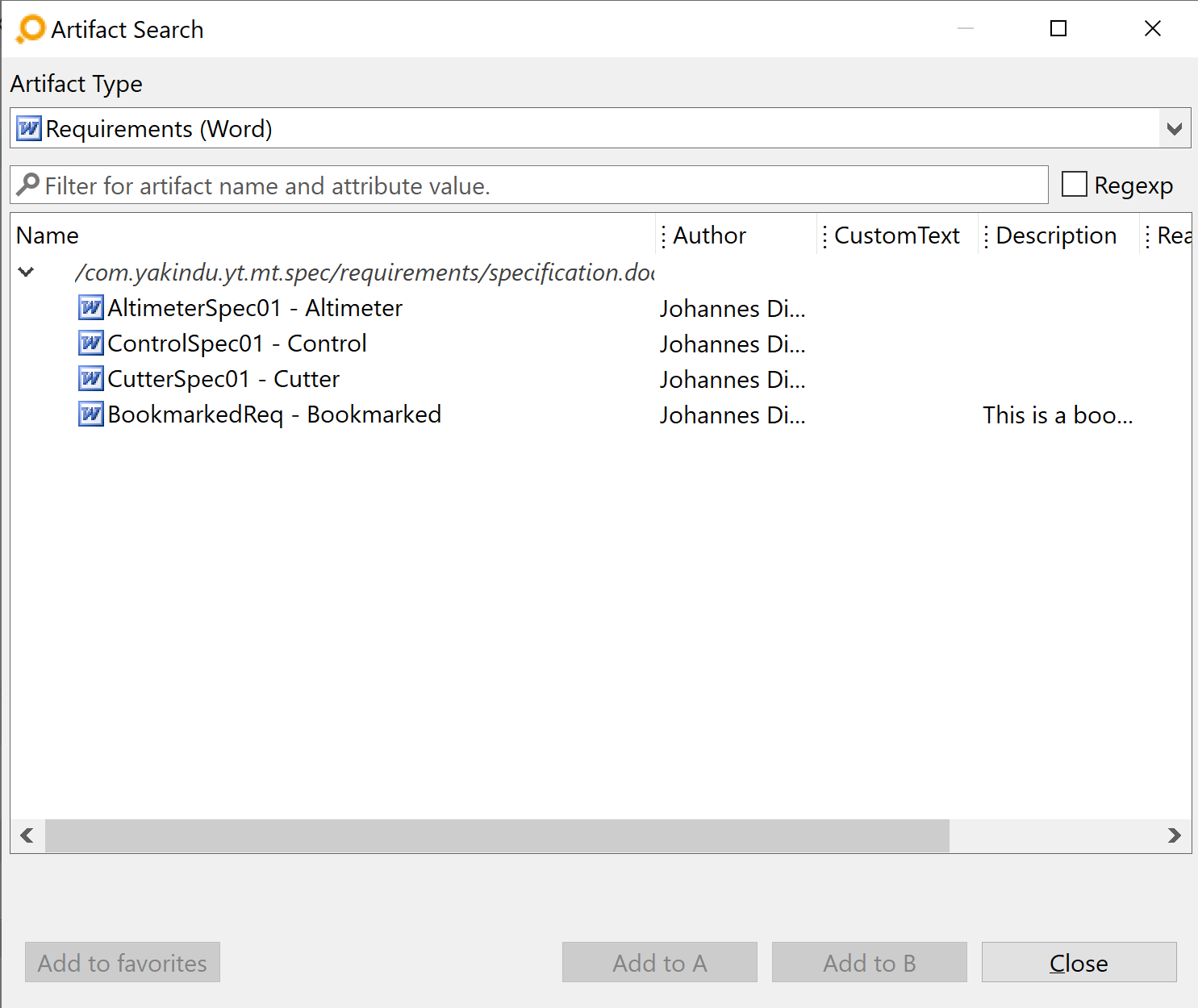
And here is the result in ANALYZE:
Use regular expressions as artifacts Copy link to clipboard
The „locate text” matcher will create an artifact for each portion of text in the document matching the specified regular expression. This matcher gives more flexibility regarding the structure of the document (in the sense that it will search text in any part of the document, including paragraphs, headings, tables...), but the configuration is highly dependent on the contents of the document.
itemis ANALYZE’s regular expression recognition relies on uniqueness. Hence, ANALYZE ignores text portions with identical
matchedText of a regular expression, e.g., if the text
REQ02 Control occurred twice in the example below. In such a case, ANALYZE will produce a single artifact (and not one per occurrence of the same text), and will attach a warning marker to this artifact (the warning will appear during Suspicious Links validation)

Caveat: As some Microsoft Word functions create duplicates of text portions, such a situation is likely to occur. For your convenience, ANALYZE doesn’t match regular expressions within Word’s internal hyperlinks, which is one of the most commonly used functions duplicating text, e.g., when creating a table of contents. So a match in a „standard” text and in a hyperlink to that text won’t be considered as duplicates. On the other hand, if a Word document has a table of contents without the hyperlinks instead of page numbers option being set, Word creates copies of the headings instead of hyperlinks, thus ANALYZE considers matches as duplicate.
Additionally, all modifications made in „Track Changes” mode are considered to be accepted, i.e., text deleted during „Track Changes” will be ignored by ANALYZE during matching. Similarly, text added in „Track Changes” mode is always taken into account.
Minimal configuration:
locate text where pattern matches ".*" {
}
This configuration will produce one artifact for each structural element of the document (heading, consecutive list of paragraphs, or cell in a table). The name of the artifact will correspond to the entire text of this structural element
Additional supported values for regular expressions Copy link to clipboard
- function matchedText: The whole match for the regular expression, the bookmarked text, or the heading.
- function textUntilNext (match | headingOrMatch) : Text portion starting from the matched text until the next match/ heading or match, resp.
- If the match itself is inside a heading, this particular heading is considered as „the next heading”, so textUntilNext(headingOrMatch) is the text portion from the match to the end of the heading.
- For the label (i.e., the name attribute), the textUntilNext() has a size restriction and will be truncated automatically. Custom attributes may have longer text passages.
Regular expression example Copy link to clipboard
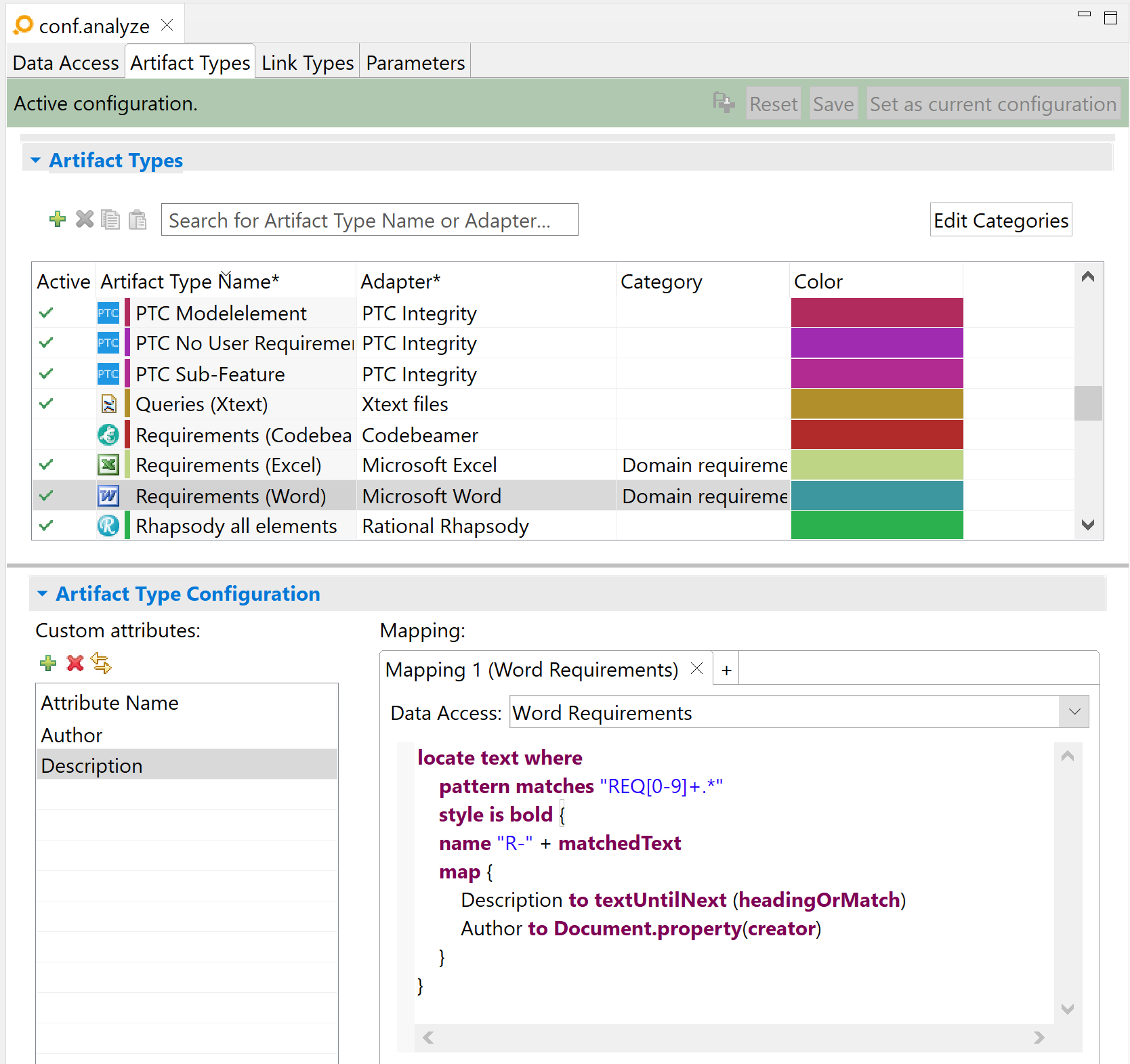
locate text where
pattern matches "REQ[0-9]+.*"
style is bold {
name "R-" + matchedText
map {
Description to textUntilNext (headingOrMatch)
Author to Document.property(creator)
}
}
In this example, the artifacts will be located in the document and will match all occurrences of the string „REQ” immediately followed by at least one digit. The expression will also include all text following this sequence, until the next end-of-line. If at least one of the matched characters is bold, then an artifact will be produced for the matched sequence.
Each artifact will have a description, corresponding to the entire text starting immediately at the end of the matched text until the beginning of the next heading or match, whichever comes first. Note that this may include a lot of text, which may span over several tables or paragraphs.
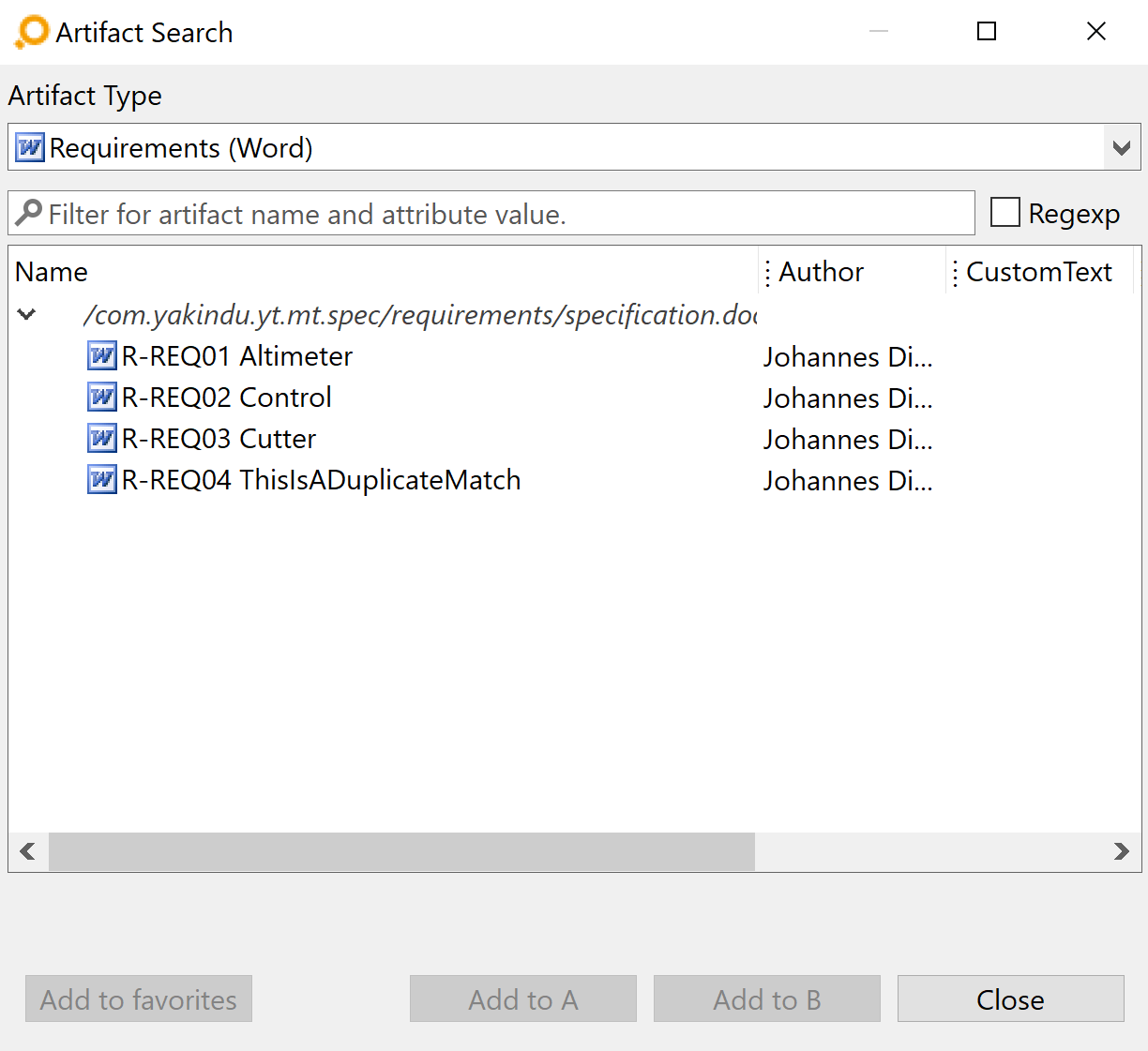
Here is a sample Word document using regular expressions:

And here is the result in ANALYZE:
Warning regarding the use of imprecise regular expressions Copy link to clipboard
If you use an imprecise regular expression while configuring the Microsoft Word adapter (for example „REQ-//d+”) more than one candidate might match.
In this example „REQ-1” and „REQ-11” would both match the expression as they both share the string „REQ-1”.
If you then double-click on the tracepoint „REQ-1” ANALYZE searches the document for the string „REQ-1” and will find the candidate „REQ-11” if it is stated above „REQ-1”!
Use headings as artifacts Copy link to clipboard
The „locate heading” matcher is really similar to the „locate text” one, except that it will only search inside Word headings, instead of the entire document. Microsoft Word comes with a set of predefined headings (Heading 1 ~ 9), but this matcher will, more generally, match any paragraph with an outline level equal or greater to 1. This also corresponds to all elements visible in the Word Outline view.
Please note: by default, the main title of a Word document does not have an outline level. Consequently, it will be ignored by the „locate heading” matcher, and will not produce an artifact.
Like the „locate text” matcher, „locate heading” will accept a parameter to filter results based on a regular expression. Note that, unlike „locate text”, this parameter is optional for headings.
Minimal configuration:
locate heading {
}
Which is equivalent to:
locate heading where pattern matches ".*" {
}
Both of these configurations will produce an artifact for each heading in the Word document. The name of the artifact will correspond to the text of the heading
Additional supported values for headings Copy link to clipboard
„locate heading” supports the same options as „locate text”. See Additional supported values for regular expressions above
Heading example Copy link to clipboard
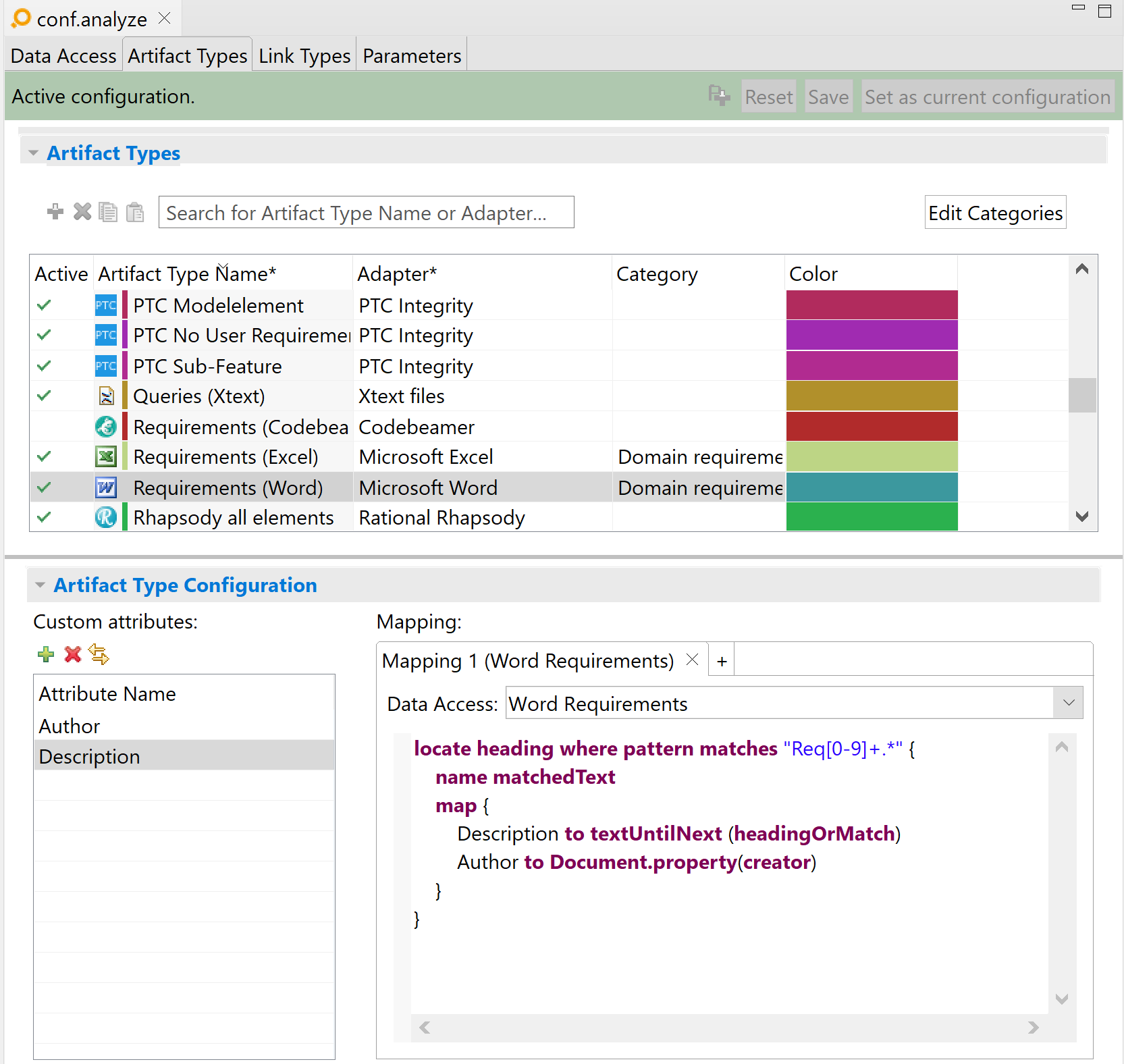
locate heading where pattern matches "Req[0-9]+.*" {
name matchedText
map {
Description to textUntilNext (headingOrMatch)
Author to Document.property(creator)
}
}
This example is very similar to the regular expression example. The main difference is that artifacts will only be produced if the text „Req” immediately followed by at least one digit is found in a heading.
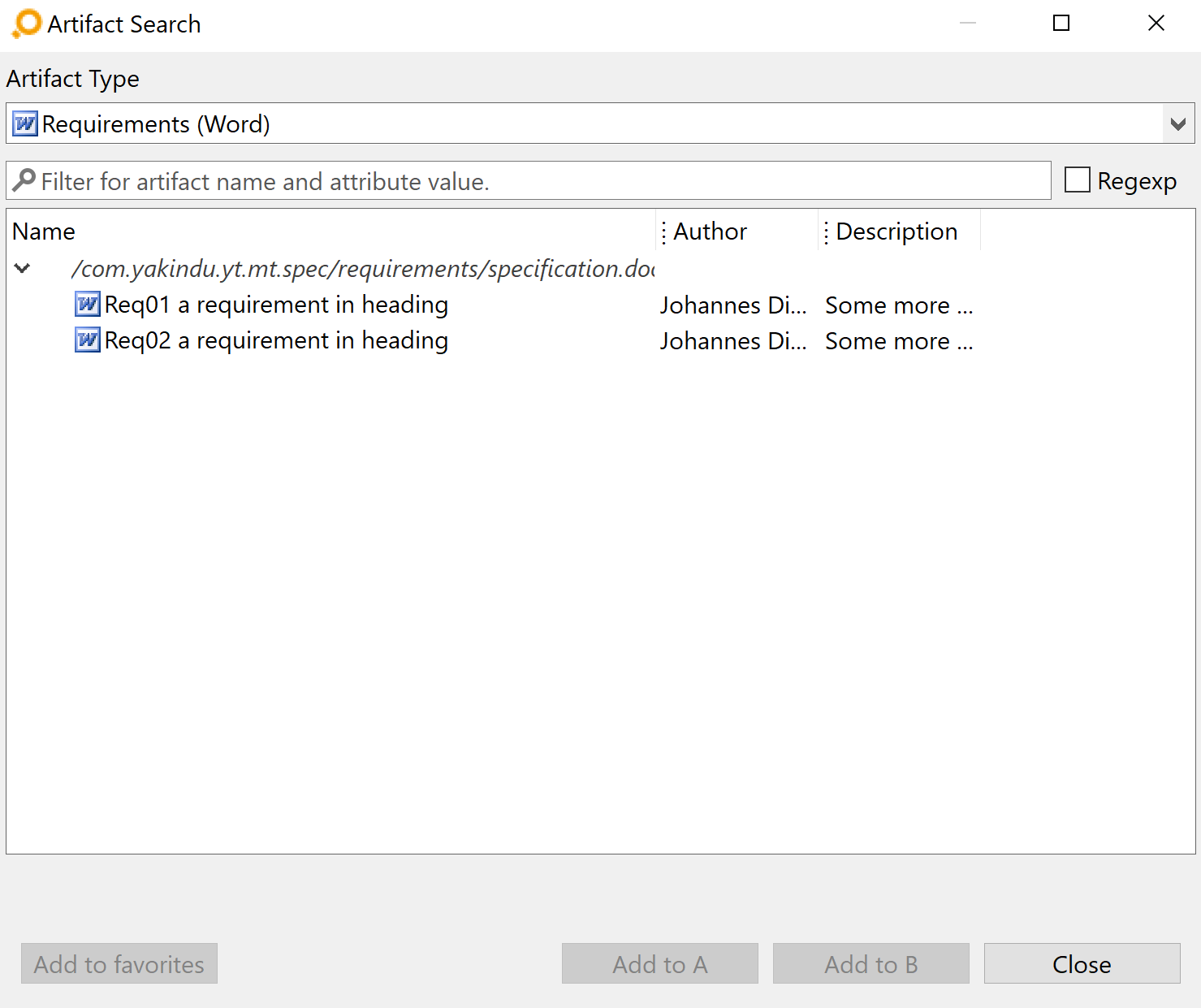
Here is a sample Word document using headings:

And here is the result in ANALYZE:
Example for a mix of bookmarks and expressions Copy link to clipboard
ANALYZE supports using a mix of resource(s) (using different configuration mappings) and recognitions specification(s) for one artifact type, e.g., by means of an adapter configuration similar to the following:
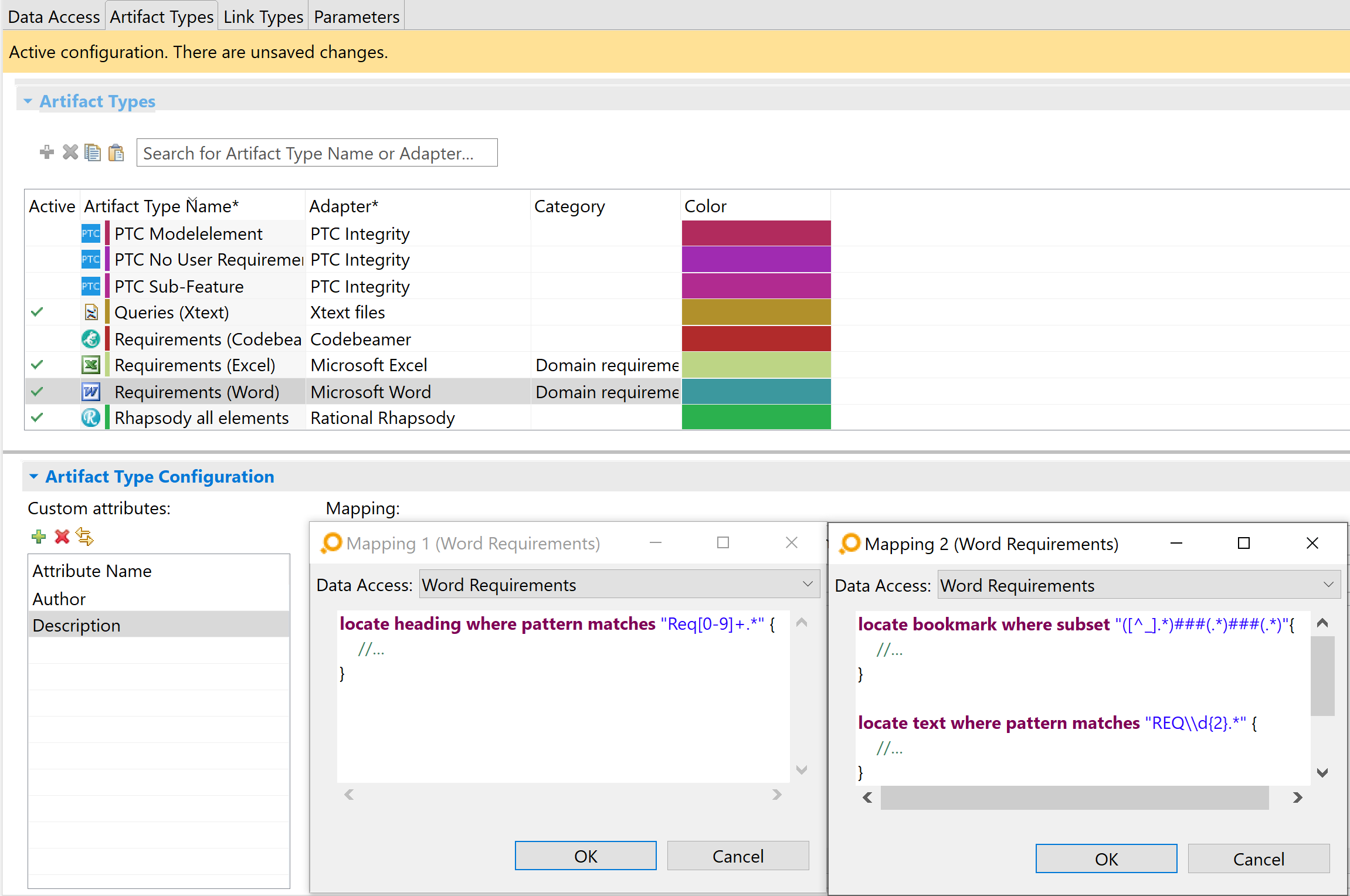
locate bookmark where subset "([^_].*)###(.*)###(.*)"{
//...
}
locate text where pattern matches "REQ\\d{2}.*" {
//...
}
locate text where pattern matches "Requirement \\d{2}.*" {
//...
}
locate heading where pattern matches "Req[0-9]+.*" {
//...
}
Support of copy and paste from Microsoft Word to ANALYZE Copy link to clipboard
In order to support fast link creation, ANALYZE supports copy and paste of artifacts from Microsoft Word to the ANALYZE Editor as described in the documentation on the ANALYZE Editor as follows:
If the clipboard contains a text portion that has been copied out of a Microsoft Word, ANALYZE analyzes the pasted text with respect to the configuration of the selected artifact type:
- If the configuration specifies bookmarks, ANALYZE analyzes the bookmarks that are contained in the clipboard text and adds each matching artifact to the ANALYZE Editor area, i.e., each artifact that both is covered by the artifact type’s configuration and that is part of the selection.
- The same holds true for regular expressions.
- Caveat: The clipboard provides information on the file the selection originates from. That filename is honored by ANALYZE during the evaluation of matching artifact. As a consequence, ANALYZE will only identify artifacts if they have been copied to the clipboard in Microsoft Word.
Propagation of selections between ANALYZE and Microsoft Word Copy link to clipboard
ANALYZE propagates the selection of artifacts from and to Microsoft Word, e.g., ANALYZE shows an artifact inside the ANALYZE Overview if a „selection” of the artifact occurs in Microsoft Word.
- ANALYZE considers an artifact based on a bookmark as selected if the user clicks on the bookmark (label) in Microsoft Word.
- ANALYZE considers an artifact based on a regular expressions as selected if a text portion is selected (marked) in Microsoft Word and this selection contains the matched text. If the selected text contains more than one match, ANALYZE considers the first one as selected. – Background: Regular expressions can match text portions of various sizes (even the whole document). Additionally, such matches can overlap. In order to clearly distinguish whether an artifact based on a regular expressions is selected, ANALYZE uses the algorithm described above. – Hint: A double/triple click in Microsoft Word selects (marks) the whole word/paragraph at the cursor location.
Migration advice (pre 1.1.1510 (3)) Copy link to clipboard
Regular expression matches had been introduced in ANALYZE version 1.1.1510 (3).
This affects the format how ANALYZE stores artifacts and links, so elder ANALYZE storage files, e.g., data.yt, need to be migrated.
A validation detecting such cases, offering quick fixes and migrating data automatically is available. Run it by selecting ANALYZE → Validation → Suspicious Links in the main menu.
Version Copy link to clipboard
An artifact’s version is used for suspicious links validation. The version of an artifact of this type is evaluated as a JSON-like concatenation of all artifact custom attribute values.