Common concepts Copy link to clipboard
The „resource” keyword Copy link to clipboard
The configuration of each adapter is adapter-specific, but some concepts are common.
The keyword resource is always followed by a pattern that denotes one or more files or folders in the Eclipse workspace. Generally a resource pattern is composed as follows:
/project_name_pattern/folder_name_pattern/folder_name_pattern/filename_pattern
That is, a resource pattern
- starts with a
/, - followed by an Eclipse project name pattern,
- followed by zero or more folder name patterns,
- followed by zero or one filename pattern.
The sequence of these components constitutes a
resource_path, also simply called
path. Adjacent path components are separated by a slash character (
/) from each other.
Each of these pattern may contain the wildcard characters
* or
?. These characters are placeholders representing actual characters in project names, folder names, or filenames, respectively. The asterisk (
*) stands for a sequence of zero or more characters, a question mark (
?) is a placeholder for exactly one character. A resource pattern may be matched by multiple actual resources, constitution a resource set. Generally a resource pattern is resolved to zero, one, or more than one actual resources.
Examples:
resource /de.itemis.pedelec.implementation.control/readme.txt
resource *.txt
resource /de.itemis*/readme.???
The first example specifies exactly one file.
The second one specifies all files (or folders or Eclipse projects) whose names are ending on the .txt filename extension.
The third example pertains to all projects starting with
de.itemis. In these projects, the resource pattern matches all file in the top-level folder beginning with
readme. followed by a three-characters extension, like, e.g.,
doc or
txt. Please note that extensions like
docx or
c do not match the pattern.
String functions Copy link to clipboard
For all adapters that support the name keyword or attribute mapping, a set of string functions is available. These allow to manipulate the original value that is read from the data source, before it is written into an artifact name or attribute.
Supported functions on basic strings are:
- trim() – Called without parameters, the trim function removes leading and trailing whitespace.
- trim( length , strategy ) – Removes leading and trailing whitespace. If the result is still longer than length, it is trimmed with regards to the strategy (one of KEEP_PREFIX, TRIM_MIDDLE, KEEP_SUFFIX).
- substringBefore( string ) – Keeps only the part of the value left from the first occurrence of a given string.
- substringAfter( string ) – Keeps only the part of the value right from the first occurrence of a given string.
- match( pattern ) – Extracts a substring from the current string that is identified by a regular expression given as a parameter. The regular expression must include exactly one group. If the whole original string matches the regular expression, the result is the substring that matches the group. If the original string doesn’t match the regular expression, the result will be the empty string.
- match( pattern , replacement ) – Replaces all substrings from the current string that match the regular expression pattern. The replacement may contain references to groups of the pattern.
- matchAll( pattern ) – Extracts a list of substrings from the current string that is identified by a regular expression given as a parameter. The regular expression must include exactly one group. For each match of the regular expression in the original string, the pattern’s group defines a substring that is part of the result list. The order in the result list is the same as the order of the matches.
- replace( string , replacement ) – Replaces all occurrences of a string by a replacement string.
- replaceAll( pattern , replacement ) – Replaces all occurrences of a string that matches a given regular expression pattern by a replacement string.
- split( separator ) – Splits the current string into a list of strings by using the separator.
- toLowerCase() – Transforms all characters in the string to lower case.
- toUpperCase() – Transforms all characters in the string to upper case.
The functions matchAll and split result in a list of strings instead of a single string. You may use all of the above functions on lists of strings. They will be applied to each individual string and the result will be a list of the result strings in the same order. When you use matchAll or split on a list of strings, the resulting substrings will be added in the positions of their respective input strings, i.e., the result will still be a flat list, not a list of lists.
Additionally, the following functions may be used on lists of strings:
- map – Replaces each element of the current list of strings by a string that is computed by the expression given as the parameter of the function. The expression can be a complex string expression, the elements of which may also be processed by string functions. The special keyword current refers to the element of the string list that is currently being processed. It is possible to use map within other map parameters. Within nested map parameters, expressions of the form current{- n } can be used to access the element that is processed by the map block n levels higher than the current one.
- join – Concatenates a list of strings to a single string by joining them with the separator that is provided as the parameter of the function.
When you split a string into a list of strings and don’t use join to turn them back into a single string, the list of strings will automatically be concatenated with ,.
Examples:
| Sample call | Result |
|---|---|
"SomeSplitAttribute".substringBefore("Split")
|
"Some"
|
"SomeSplitAttribute".substringAfter("split")
|
"Attribute"
|
"Some\\Attribute".replace("\\", "/")
|
"Some/Attribute"
|
"SomeSomeGroupInAttribute".replaceAll(".*(SomeGroupIn).*", "-")
|
"Some-Attribute"
|
"SomeAttributeValue".trim(8, KEEP_PREFIX)
|
"SomeAtt..."
|
"SomeAttributeValue".trim(8, KEEP_SUFFIX)
|
"...teValue"
|
"SomeAttributeValue".trim(8, TRIM_MIDDLE)
|
"Some...lue"
|
"SomeSomeGroupInAttribute".match(".*(SomeGroup).*")
|
"SomeGroup"
|
"Some SomeGroupInAttribute SomeOtherGroup".matchAll(".*(Some\\w*Group).*")
|
"SomeGroup,SomeOtherGroup"
|
"SomeSplitAttributeSplitAttribute".split("Split")
|
"Some,Attribute,Attribute"
|
"SomeSplitAttributeSplitAttribute".split("Split").join("; ")
|
"Some; Attribute; Attribute"
|
"One/Two/Three".split("/").map("["+current+"]")
|
"[One],[Two],[Three]"
|
"One/Two/Three;A/B/C".split(";").map(current.split("/").join(", ")).join(" - ")
|
"One, Two, Three - A, B, C"
|
Regular expressions Copy link to clipboard
Regular expressions
are a powerful means for
find or
find and replace operations on character strings. A regular expression, also known as
regex or
regexp, is a sequence of characters that defines a search pattern. For example, the regex
aaa.*bbb specifies a search pattern matching strings consisting of the letters „aaa”, followed by a (possibly empty) sequence of arbitrary characters, followed by the letters „bbb”.
You can use regular expression in many places when setting up your itemis ANALYZE configuration. ANALYZE supports regular expressions as defined by the Java programming language or, to be more exact, by the java.util.regex.Pattern class.
Java regular expressions are very similar to Perl regular expressions. However, please note that there are a few differences!
Text-Until-Next pattern Copy link to clipboard
There is a very common scenario of a regular expression we want to show you. It is called Text-Until-Next and means, that the regular expression match the whole text until the next match is found. It also solves a problem, that if a matched section contains too many characters, individual matches may no longer be found. The pattern will in general look like this:
(?sm)(^[A][B][C])(.+?(?=\\z|[A])
The above formula contains placeholder [A], [B] and [C]. So you will replace these on your own, also the brackets will be replaced.
We will break this formula into two different parts for an easier explanation.
Part one contains (?sm)(^[A][B][C]) and find the given requirements specifications
- (?sm) is important, if the matched is more than one line long.
- ^ means, that [A] must be the first expression in the line to match.
- [A] set the requirements identification.
- [B] set the name of the requirements. If you want that this can be every character, than use .*?
- [C] set the end of the requirements name. This can be e.g. a line end \n.
Part two contains (.+?(?=\\z|[A]) and groups the following text from the previously found requirement from part one to the next match or to the end of the document.
- .+? will match everything if there is at least one character
- ?= is a positive look-ahead assertion, which means that the expression must follow the aforementioned expression
- \\z symbolizes the end of the document.
An example can be looked like:
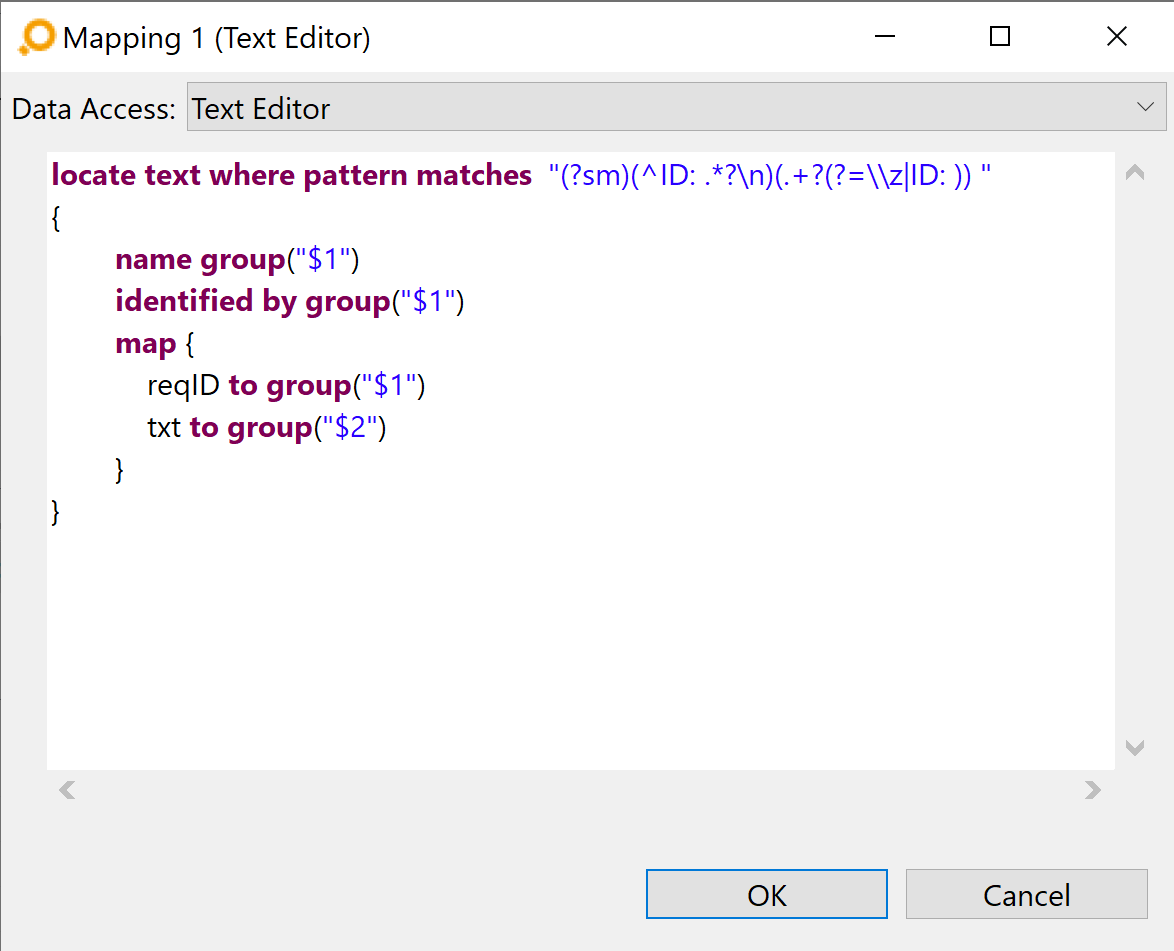
(?sm)(^ID: .*?\n)(.+?(?=\\z|ID: )
Here the requirements identification [A] is set to
ID: and must be the first element in the line because of the
^. The name of the requirements [B] can be everything
.*? and the name of the requirements [C] ends with a linebreak
\n. The ID and the name of the requirements will be in the first group $1 and the text will be in the second group $2.
So a complete configuration with the groups as mapping looked like this:
RegEx Tester Copy link to clipboard
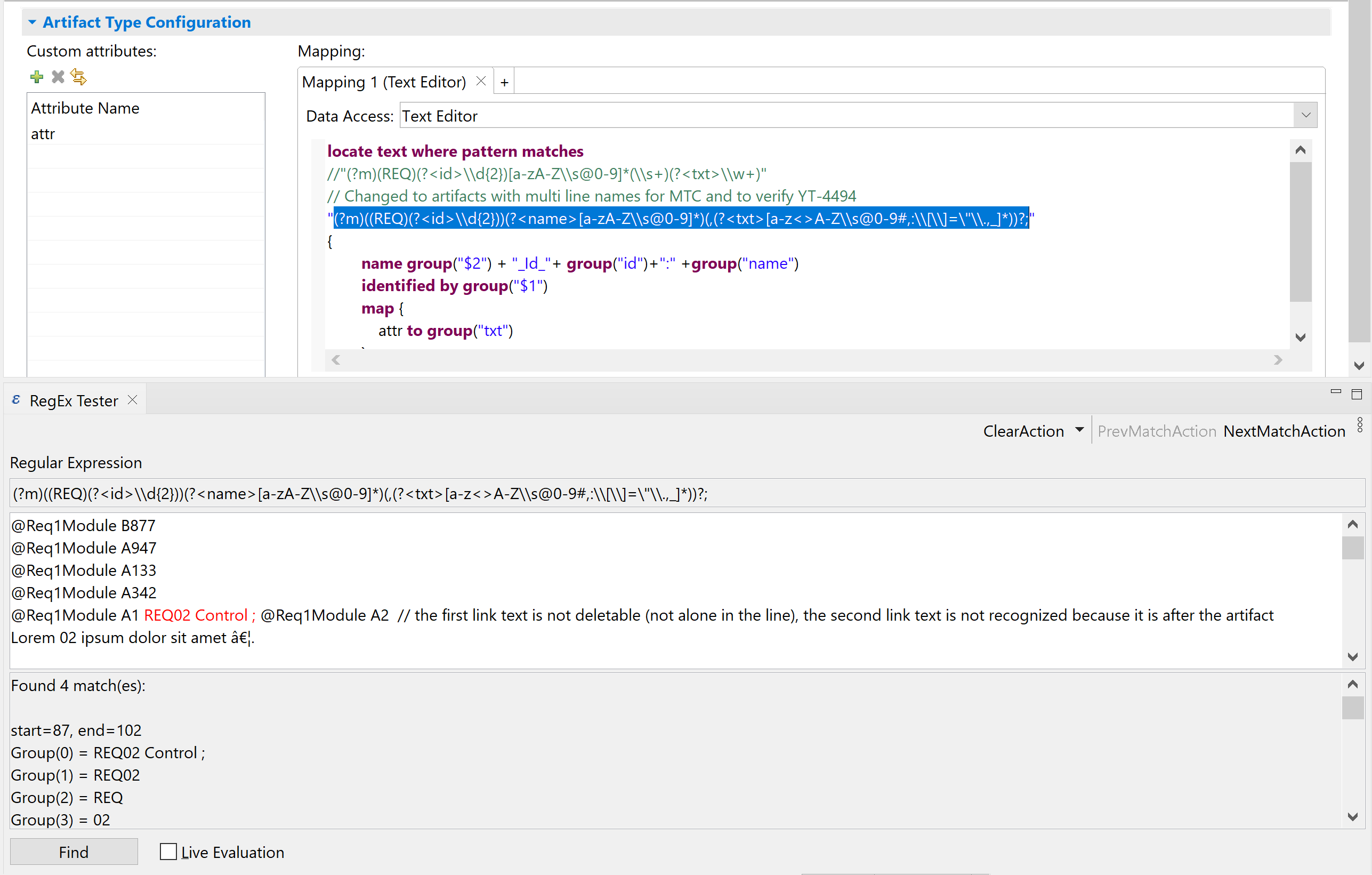
„RegEx Tester”, A view in itemis ANALYZE enables you to test your regular expression. You can open this view via Window → Show View → Other... → RegEx Tester. Everywhere in your itemis ANALYZE configuration, where regular expression is used, there is a hyperlink on the regular expression. By pressing this hyperlink via ([Ctrl]+left mouse), the RegEx Tester view will open automatically and insert the selected regular expression in the view.
Example:
In this example, we clicked on the hyperlink of the regular expression in the itemis ANALYZE configuration. This opens the new view „RegEx Tester” and import the regular expression which was selected. Then we can test the regular expression by inserting text in the box below. After pressing „Find”, the view shows where the text matches the regular expression and highlights in red. Also in the box at the bottom shows more details of the findings. Now you can easily adjust or write your regular expression and get feedback instantly.
Condition expressions Copy link to clipboard
Condition Expressions helps user to provide suitable expressions based on certain conditions. The decisions are taken at the runtime based on the value in the condition provided. itemis ANALYZE currently supports 2 types of conditions expressions i.e.
- If-else-if ladder : This is an expression with if and else if conditions similar to any other programming languages (syntax might vary but working remains the same).
Example : Here in this example based on different conditions output from the if-else ladder varies. if attribute („Name”) contains „Contract” then output shall be – Contract else it will check for remaining conditions and provide suitable outputs, If none of the conditions match then statement in the else block would be the output.
if (attribute ("Name") contains "Contract" ){
valueOf("Name") + "- Contract"
}else if (attribute ("Name") contains "Employee" ){
"- Employee"
}else if (attribute ("Name") contains "Permanent" ){
"- Permanent"
}else{
"- Others"
}
- Switch Expression : Switch expression helps user to decide output based on the expected values.
Example : Here in the example output varies based on the value of attribute(„Name”). If attribute („Name”) is „Lenny” then output will be „Lenny Holmes” similarly for other cases. If no case matches then output in the default statement will be provided.
switch (attribute ("Name")) {
case "Lenny" : "Lenny Holmes"
case "Alex" : "Alex G"
default : "Unknown Author"
}
Note : Most of the expressions like attributes/ string functions described in this documentation can be used in if-else blocks or case parts if it makes sense.